
![[플랭고] 반정규화 + Lock vs 정규화 + 서브쿼리 - 누가 더 빠를까](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FmWv8g%2FbtsufkhGSrw%2Fb9C3liyXuvyss45zGkUJck%2Fimg.png)
배경
플랭고 앱 개발 중 기존에는 일정과 회원이 일대일로 대응되었는데 '함께 할 친구' 기능을 추가하면서 일정과 회원의 관계가 일대다로 변경되었다. 이에 따라 기존 조회, 수정 로직 등이 많이 변경되었는데 다른 부분은 모두 변경을 마치고 '일정 목록 조회' 기능에서 고민되는 부분이 생겼다.
현재 Schedule 테이블에 일정 관련 정보가 있고, ScheduleMember 테이블에 일정에 참여하는 회원에 대한 정보가 담겨있는데 앱에서 일정 목록 조회 시 다음과 같이 일정에 참여하는 회원 수를 표시해주기 위해서 목록 조회 시 Schedule과 ScheduleMember를 같이 조회해야 되는 상황이 생겼다.
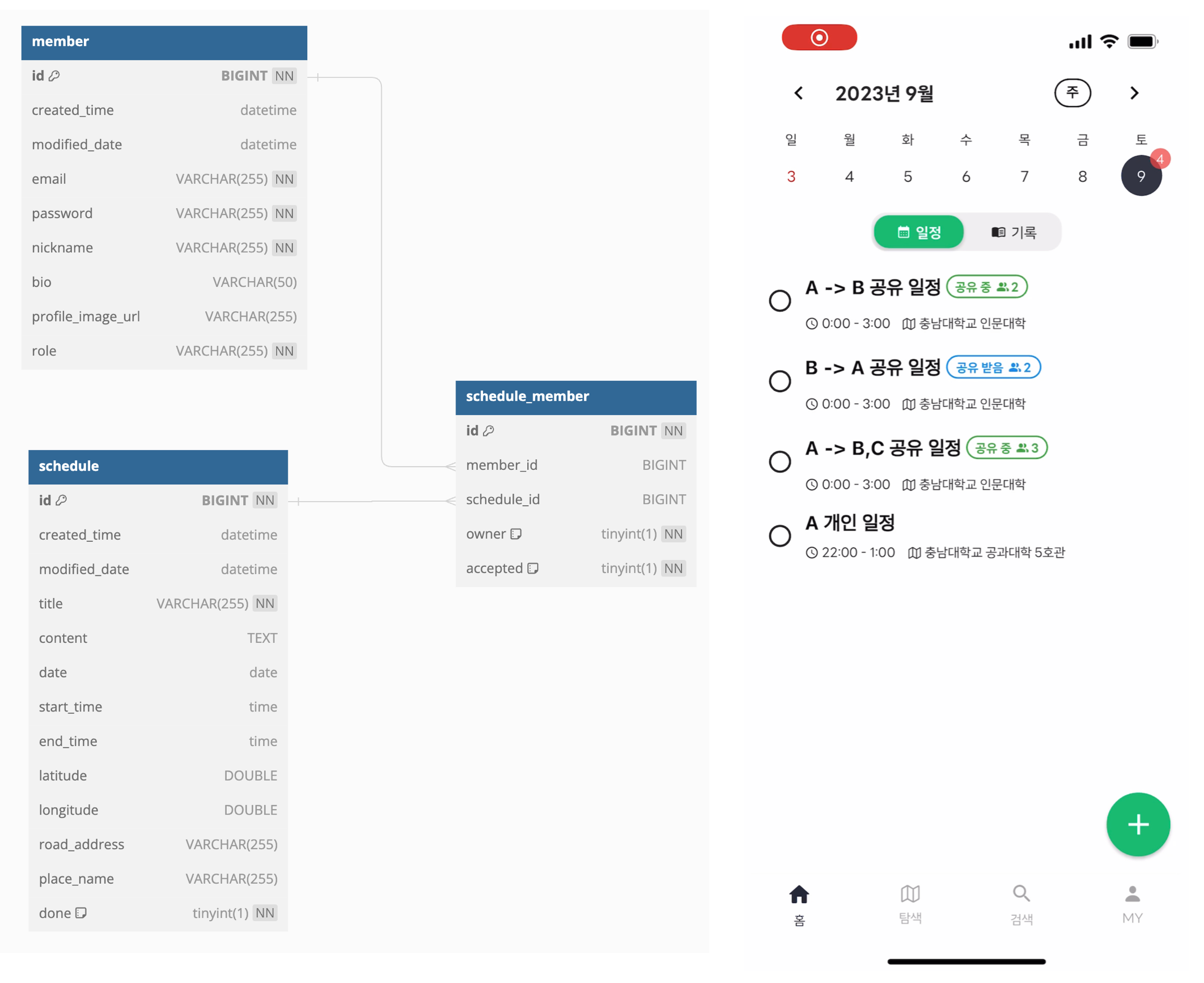
이를 구현하기 위해 여러 방법을 사용할 수 있을 것 같았지만 각 방법 별 성능 차이를 확인하고 싶어서 jmeter를 사용해 직접 성능을 측정해보았다.
테스트 준비
테스트에 사용할 api 들
성능 테스트는 일정 목록을 조회하는 api와 '함께할 친구'를 변경하는 api를 호출하여 각각의 response time을 측정하는 방법으로 진행했다. 일반적으로 일정 참여 회원의 변경 요청보다는 목록 조회가 많을 것이므로 일정 목록을 50번 조회할 때 회원 변경 요청이 2번 이뤄진다고 가정하고 테스트를 진행했다.
1. 일정 목록 조회 api
@GetMapping(params = "date")
public List<ScheduleListResponseDto> findAllByDate(
@LoginMember Long memberId,
@DateTimeFormat(pattern = "yyyy-MM-dd") @RequestParam("date") LocalDate requestDate) {
return scheduleService.findAllByDate(memberId, requestDate);
}다음과 같이 호출해 사용할 수 있다.
GET /api/auth/schedules?date=yyyy-MM-dd2. 함께할 친구 변경 api
@PostMapping
public void invite(@LoginMember Long memberId,
@PathVariable Long scheduleId,
@RequestBody @Valid ScheduleMemberAddRequestDto requestDto) {
scheduleMemberService.invite(memberId, scheduleId, requestDto);
}다음과 같이 호출한다.
POST /api/schedules/{scheduleId}/members
{"memberId" : "{memberId}"}테스트 데이터 입력 & jmeter 설정
테스트를 진행하기 위해 먼저 100명의 회원을 생성하고 각 회원이 공유하지 않는 일정 5개와 공유하는 일정 2개를 갖도록 @PostConstruct를 사용해 데이터를 입력해주었다.
@PostConstruct
public void dataInit() {
// 회원 100명 가입
// user1, user2, ..., user100
IntStream.rangeClosed(1, 100)
.mapToObj(number -> SignupRequestDto.builder()
.nickname("user" + number)
.password("1111")
.email(number + "@gmelon.dev")
.build())
.forEachOrdered(authService::signup);
List<Member> members = memberRepository.findAll();
// 회원 별 자신이 소유하는 일정 5개 생성
int singleScheduleCountPerMember = 5;
for (Member member : members) {
for (int i = 0; i < singleScheduleCountPerMember; i++) {
Schedule schedule = Schedule.builder()
.title("일정")
.content("내용")
.date(LocalDate.now())
.startTime(LocalTime.now())
.build();
schedule.setSingleOwnerScheduleMember(member);
scheduleRepository.save(schedule);
}
}
// 회원 별 랜덤한 다른 회원 2명과 공유하는 일정 2개 생성
int shareScheduleCountPerMember = 2;
ThreadLocalRandom random = ThreadLocalRandom.current();
for (Member member : members) {
for (int i = 0; i < shareScheduleCountPerMember; i++) {
Member firstMember = members.get(random.nextInt(100));
while (firstMember.getId().equals(member.getId())) {
firstMember = members.get(random.nextInt(100));
}
Member secondMember = members.get(random.nextInt(100));
while (secondMember.getId().equals(member.getId()) || secondMember.getId().equals(firstMember.getId())) {
secondMember = members.get(random.nextInt(100));
}
ScheduleCreateRequestDto requestDto = ScheduleCreateRequestDto.builder()
.title("일정")
.content("내용")
.date(LocalDate.now())
.startTime(LocalTime.now())
.participantIds(List.of(firstMember.getId(), secondMember.getId()))
.build();
scheduleService.create(member.getId(), requestDto);
}
}
}그리고 테스트를 수행하기 위해 다음과 같이 jmeter Test Plan을 작성했다.
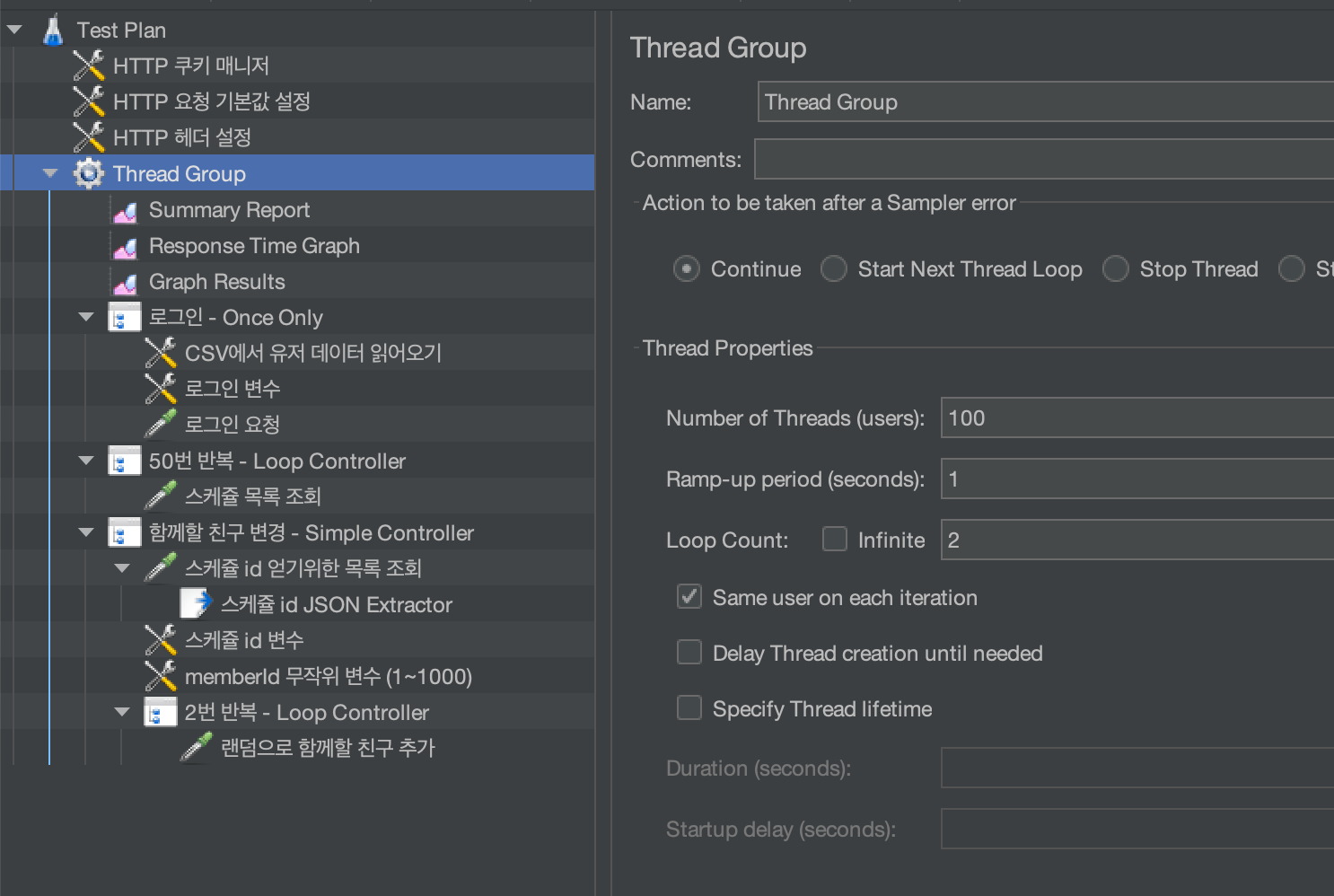
간단히 설명하면, csv 파일에 작성된 회원 닉네임과 비밀번호 를 읽어 로그인을 수행하고 (HTTP 쿠키 매니저를 통해 사용자별 쿠키를 유지) 각 회원 별로 스케쥴 목록 조회를 50번 수행하고 함께할 친구 추가를 2번 수행하는 과정을 총 2회 반복한다.
그림으로 보면 아래와 같은 과정으로 테스트를 진행한다.
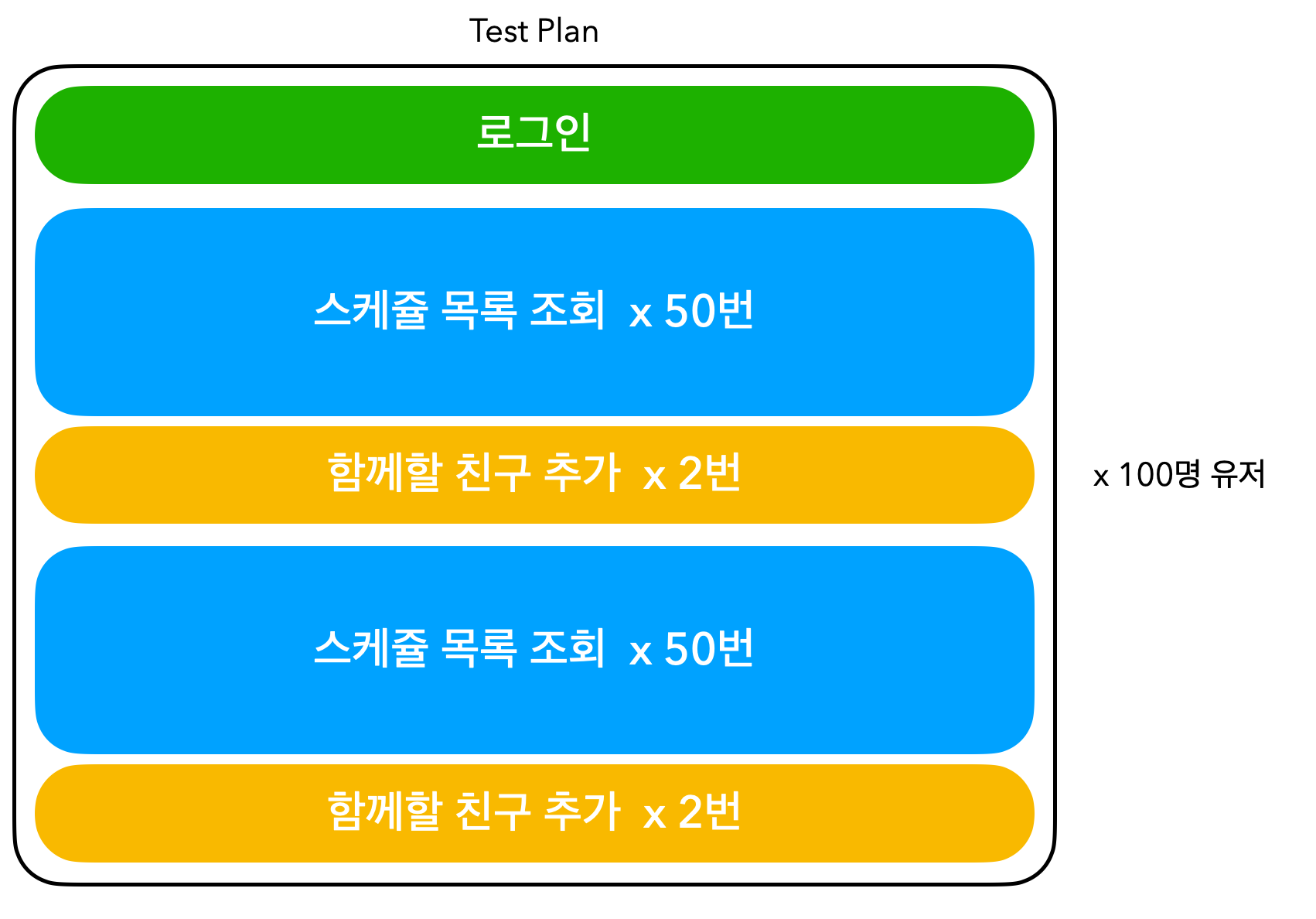
테스트 진행
설정을 마치고 실제 성능 테스트를 진행했다.
1. 정규화 & N + 1 쿼리
앞서 이야기한 '일정 목록 조회 시 일정에 참여하는 회원 수 함께 조회' 라는 문제를 해결하기 위해 먼저 기존 테이블대로 정규화를 유지하고 매번 일정 목록 조회 시 마다 일정(schedule)에 해당하는 일정 회원(scheduleMember)이 몇 개가 존재하는지 애플리케이션에서 추가 쿼리를 날리는 방법을 생각해봤다.
즉 아래와 같이 코드가 작성된다.
ScheduleQueryRepository
@Query("select new dev.gmelon.plango.domain.schedule.query.dto.ScheduleListQueryDto(" +
"s.id, s.title, s.content, s.date, s.startTime, s.endTime, sm.owner, sm.accepted, " +
"s.latitude, s.longitude, s.roadAddress, s.placeName, s.done) " +
"from Schedule s join s.scheduleMembers sm " +
"where sm.member.id = :memberId " +
"and s.date = :date " +
"order by case when s.startTime is null then 0 else 1 end, " +
"case when s.startTime is null then s.modifiedDate else s.startTime end asc, " +
"s.endTime asc")
List<ScheduleListQueryDto> findAllByMemberIdAndDate(@Param("memberId") Long memberId, @Param("date") LocalDate date);ScheduleService
Repository에서 조회한 ScheduleListQueryDto 를 api의 응답으로 나갈 ScheduleListResponseDto 로 변환할 때 회원 수를 조회하기 위해 schduleMemberRepository의 메서드를 매번 호출하게 된다.
public List<ScheduleListResponseDto> findAllByDate(Long memberId, LocalDate requestDate) {
List<ScheduleListQueryDto> schedules = scheduleQueryRepository.findAllByMemberIdAndDate(memberId, requestDate);
return schedules.stream()
.map(schedule -> ScheduleListResponseDto.from(schedule, scheduleMemberRepository.countByScheduleId(schedule.getId())))
.collect(toList());
}서비스 계층에서 조회한 일정별로 다시 쿼리를 날려야 하기 때문에 (scheduleMemberRepository.countByScheduleId()) N + 1 쿼리 문제가 발생하게 된다. 성능을 측정해보면 다음과 같이 나온다.
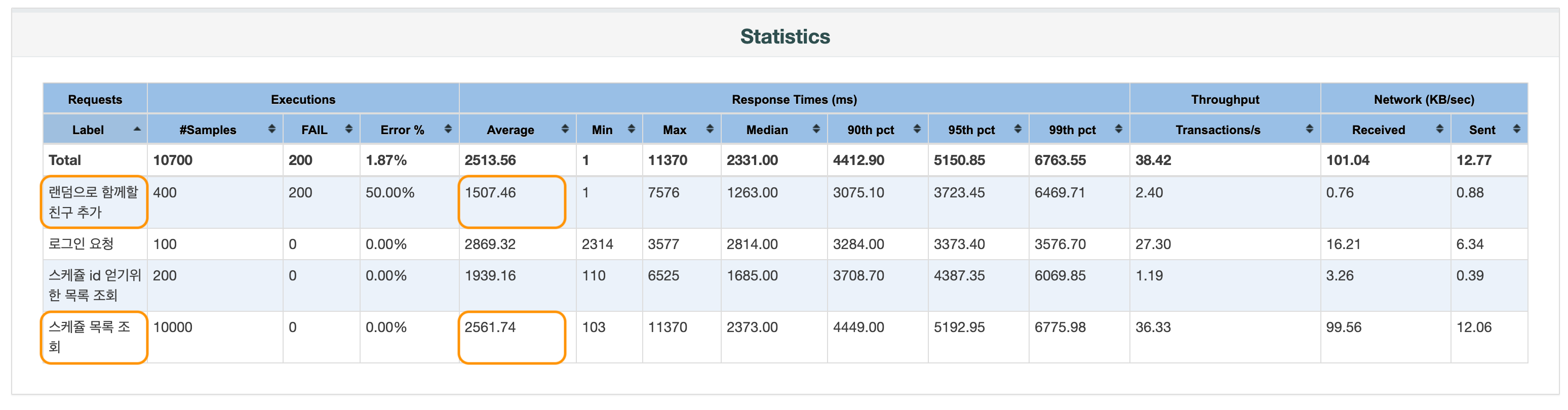
테스트 중 발생한 에러는 1 - 1000 사이의 id 중 랜덤하게 택한 id를 갖는 회원을 함께할 친구로 추가할 때 이미 함께할 친구로 지정되어 있어서 발생하는 오류로 우선 무시하고, 스케쥴 목록 조회와 함께할 친구 추가에 소요된 평균 시간을 확인했다. 각각 2561ms, 1507ms로 측정되었다. 즉, 평균적으로 목록을 조회하는데 2.5초가 걸렸다는 의미이다. 빠르다고는 할 수 없는 시간이지만 다른 결과가 없어 비교하기가 어려워 우선 나머지 항목들도 마저 측정해보았다.
2. 정규화 & select 절 서브 쿼리
다음으로는 1번 경우와 마찬가지로 정규화를 유지하지만, 애플리케이션 레벨에서 쿼리를 추가로 날리는 것이 아니라 db 레벨에서 서브 쿼리를 날려 원하는 값을 조회하는 방법이다.
코드는 다음과 같이 작성된다.
ScheduleQueryRepository
select 절에서 서브 쿼리를 사용해 현재 스케쥴 id를 schedule_id로 갖는 ScheduleMember의 row 개수를 조회한다.
@Query("select new dev.gmelon.plango.domain.schedule.query.dto.ScheduleListQueryDto(" +
"s.id, s.title, s.content, s.date, s.startTime, s.endTime, (select count(*) from ScheduleMember sm where sm.schedule.id = s.id), " +
"sm.owner, sm.accepted, s.latitude, s.longitude, s.roadAddress, s.placeName, s.done) " +
"from Schedule s join s.scheduleMembers sm " +
"where sm.member.id = :memberId " +
"and s.date = :date " +
"order by case when s.startTime is null then 0 else 1 end, " +
"case when s.startTime is null then s.modifiedDate else s.startTime end asc, " +
"s.endTime asc")
List<ScheduleListQueryDto> findAllByMemberIdAndDate(@Param("memberId") Long memberId, @Param("date") LocalDate date);ScheduleService
따라서, ScheduleService는 다음과 같이 추가로 쿼리를 날리지 않는 방식으로 개선될 수 있다.
public List<ScheduleListResponseDto> findAllByDate(Long memberId, LocalDate requestDate) {
List<ScheduleListQueryDto> schedules = scheduleQueryRepository.findAllByMemberIdAndDate(memberId, requestDate);
return schedules.stream()
.map(ScheduleListResponseDto::from)
.collect(toList());
}이 경우에 성능을 측정해보면 다음과 같은 결과가 나오게 된다.
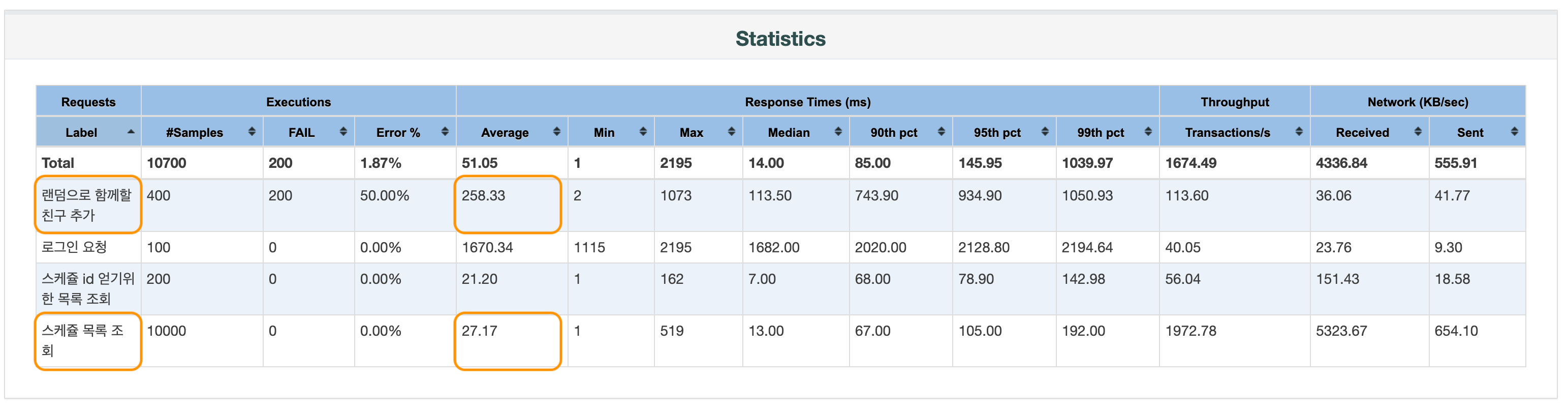
솔직히 좀 깜짝놀랐다. 이전 테스트와 비교해 너무 빨리 끝나서 처음엔 테스트가 제대로 안 된건줄알고 다시 돌려보기도 했다. '함께할 친구 추가' api의 응답 시간은 1507ms에서 258ms로 5.84배 가량 빨라졌고 특히 '스케쥴 목록 조회' api의 응답 시간은 2561ms 에서 27ms로 94배 가량 빨라졌다. N+1 쿼리 문제.. 많이 들어보기는 했지만 이렇게 직접 수치로 확인하니 더 와닿았다. 그냥 N+1은 절대 있어서는 안 되는 것인가 보다.
사실 여기까지 테스트를 해보고 조금 허무한 것도 있었는데 왜냐하면 처음에 이 글을 기획할 때 제목이 '반정규화를 통한 조회 성능 개선기' 였기 때문이다..ㅎ 원래는 반정규화를 딱 해서 성능이 탁 증가되는걸 보고 싶었던 건데 서브쿼리로 조회하는 게 생각보다 성능 저하가 별로 없어보여서 이대로 사용해도 될까? 하는 생각을 하게 되었다. 그래도 궁금하니까 마지막으로 비정규화를 했을 때 성능이 얼마나 개선되는지도 계속해서 테스트를 해보았다.
3. 반정규화 & 비관적 Lock
우선 반정규화를 하기 위해 다음과 같이 Schedule 테이블에 memberCount 라는 필드를 두고 '함께할 친구'를 추가하고 삭제할 때마다 이 값을 변경하도록 했다.
Schedule
@Getter
@NoArgsConstructor(access = PROTECTED)
@Entity
public class Schedule extends BaseTimeEntity {
/*생략*/
@Column(nullable = false)
private int scheduleMemberCount;
public void increaseScheduleMemberCount() {
this.scheduleMemberCount++;
}
public void decreaseScheduleMemberCount() {
this.scheduleMemberCount--;
}
/*생략*/
}ScheduleMemberService
기존에는 ScheduleMember 테이블에 쿼리를 날리는 것으로 '함께할 친구'의 수를 알 수 있었지만, 반정규화를 하면 추가로 쿼리를 날리지 않고 Schedule의 필드를 그대로 반환하게 되기 때문에 ScheduleMember 테이블의 값이 변경될 때 마다 Schedule 테이블의 값도 함께 변경해주어야 한다. 따라서 다음과 같이 ScheduleMemberService에서 연관된 Schedule의 scheduleMemberCount를 변경해주도록 한다. 추가, 수정, 삭제 등 모든 곳에 반영되어하며 예시로는 추가 코드만 가져왔다.
@Transactional
public void invite(Long scheduleOwnerMemberId, Long scheduleId, ScheduleMemberAddRequestDto requestDto) {
Schedule schedule = findScheduleById(scheduleId);
validateOwner(schedule, scheduleOwnerMemberId);
Long newMemberId = requestDto.getMemberId();
validateMemberNotExists(schedule, newMemberId);
saveNewScheduleMember(newMemberId, schedule);
// 연관된 Schedule의 scheduleMemberCount를 증가시킨다
schedule.increaseScheduleMemberCount();
}그런데 이렇게 하니, 동시에 여러 회원이 '함께할 친구'를 변경할 때 동시성 문제로 Schedule이 갖는 memberCount와 ScheduleMember 테이블의 개수가 일치하지 않는 문제가 종종 발생하는 것을 확인했고 이를 방지하기 위해 DB 레벨에 Lock을 걸어주었다.
ScheduleRepository
@Query("select s from Schedule s " +
"join fetch s.scheduleMembers sm " +
"join fetch sm.member " +
"where s.id = :id")
@Lock(LockModeType.PESSIMISTIC_WRITE)
@QueryHints({@QueryHint(name = "jakarta.persistence.lock.timeout", value = "10000")})
Optional<Schedule> findByIdWithScheduleMembersWithLock(@Param("id") Long scheduleId);참고로 @Lock은 distinct와 같이 사용할 수 없다고 한다. 동시에 사용하려고 하면 InvalidDataAccessResourceUsageException 이 발생한다. 하지만 JPQL에서 distinct 키워드를 사용하지 않으면 일대다 관계에서 다쪽 row의 개수 만큼 일쪽 엔티티가 뻥튀기(?) 되는 잘 알려진 문제가 있다. distinct를 빼고 다시 실행해보니 예외가 발생하지 않고 동작은 잘 했지만 확인해보니 반환 타입이 List<Schedule> 로 되어있는 경우 역시나 ScheduleMember의 개수만큼 동일한 Schedule 객체가 리스트에 중복되어 포함되는 것을 확인할 수 있었다.
List<Schedule> 을 반환하는 ScheduleRepository

ScheduleMemberService

디버깅 결과
(ScheduleMember의 개수만큼 Schedule이 중복된다)
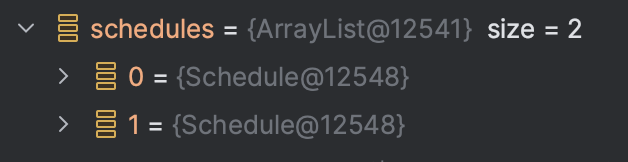
다만 이것이 문제가 되는 이유가 단일 row가 아니라 여러 row를 조회할 때 예상했던 row보다 많은 row가 조회되어 그 후의 로직이 의도한대로 동작하지 않는 것이라고 한다면, 이 경우에는 어차피 (리스트가 아닌) 하나의 Schedule만을 조회하는 것이고 위와 같이 동일한 주소의 객체가 조회되기 때문에 그 중 하나만 사용하도록 하면 괜찮은게 아닐까? 하는 생각을 했다. 테스트해보니 메서드의 반환 타입을Optional<Schedule> 로 해두면 JPA는 조회되는 여러 Schedule 중 첫번째를 반환해주고 있기도 해서 우선 이렇게 두고 사용하기로 했다.
ScheduleMemberService
서비스에서도 락을 획득하는 메서드를 사용해 schedule를 조회하고 count를 변경해주었다.
private Schedule findScheduleByIdWithLock(Long scheduleId) {
return scheduleRepository.findByIdWithScheduleMembersWithLock(scheduleId)
.orElseThrow(NoSuchScheduleException::new);
}이렇게 반정규화와 Lock을 사용해 문제를 해결하는 방법의 성능은 다음과 같았다.
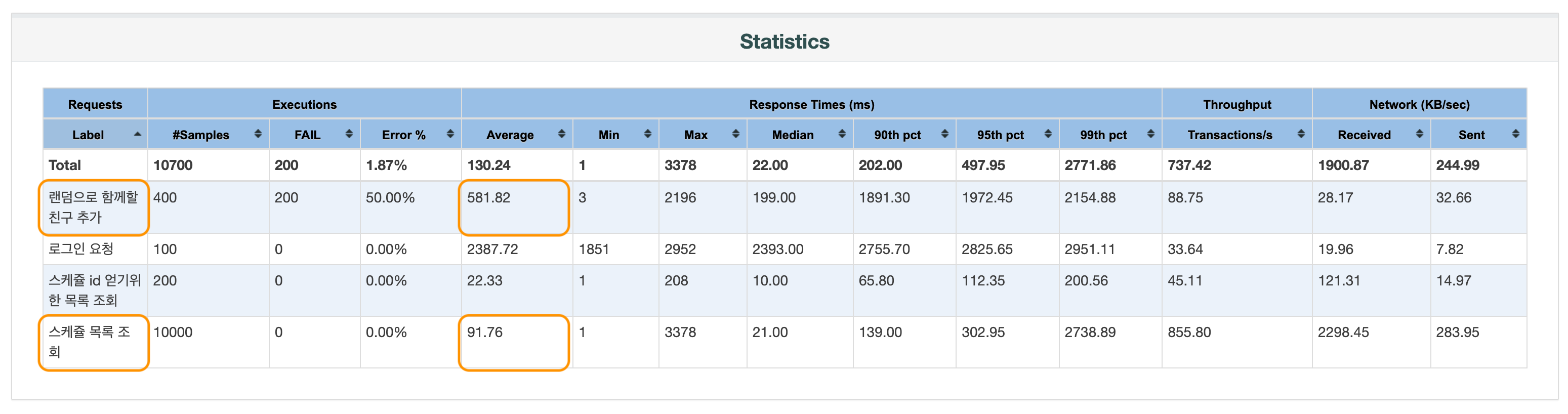
스케쥴 목록 조회는 91ms, 함께할 친구 추가는 581ms 정도가 걸렸다. 정규화 + N+1 쿼리 방식보다는 훨씬 빠르지만 이 방식은 Lock을 획득하고 반환하는 과정이 존재하기 때문에 Lock이 없을 때보다는 읽기, 쓰기 시간이 더 소요된다. 때문에 정규화 + 서브쿼리 방식보다는 조금씩 더 시간이 걸리는 것을 확인할 수 있다.
결론
3가지 경우의 결과를 표로 정리해보면 다음과 같다.
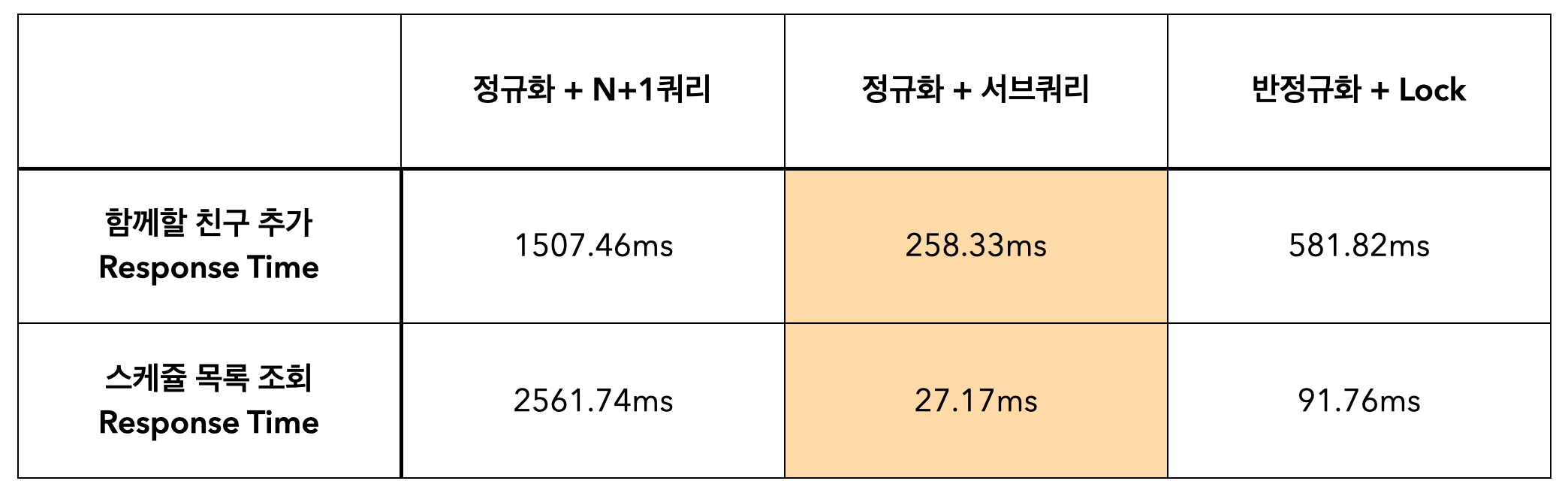
막연하게 서브쿼리는 사용하면 안 된다고 생각해서 처음에 당연히 이 문제를 반정규화로 풀어야겠다고 생각했었는데 예상과는 다른 결과가 나와서 놀랐고 좋은 공부가 되었던 것 같다. 잘 모르지만 서브쿼리의 where 절에서 인덱스가 걸려있는 컬럼을 사용했기 때문에 성능에 큰 영향이 없었던게 아닐까 생각이 들었다. 나름 고민해서 구성하고 측정한 성능 테스트 결과가 있어서 개발 중인 프로젝트인 플랭고에서는 우선 정규화 + 서브쿼리로 이 문제를 푸는 것으로 결정 내릴 수 있었다.
이전부터 데이터베이스에 대한 깊이 있는 지식이 부족하다고 느껴서 며칠 전 이펙티브 자바 스터디 팀원들에게 Real MySQL 책에서 실행 계획, 인덱스 부분 정도라도 같이 읽어보자고 얘기했었는데 이 부분 잘 공부해서 서브쿼리나 옵티마이저 같은 내용을 좀 더 확실히 알아두면 좋겠다는 생각이 들었다.
![[플랭고] 프로젝트 앱스토어 / 플레이스토어 배포 회고](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FLcw8v%2FbtsCwbEOQYY%2FGffknxEWoOuIdd9h8X0b10%2Fimg.png)
![[플랭고] 회원 가입 프로세스 개선하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FdBJyQP%2FbtsBVDulm0B%2Fk9vCMxw5lwkhkY8INOHa0k%2Fimg.png)
![[해커톤 후기] 플랭고 앱 개발기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fbgjt4I%2FbtrWQIQNIiQ%2FdZ6N8knYo1N9iKoKpl7aH0%2Fimg.png)