
Collectors의 groupingBy() 메서드를 사용하면 아래와 같이 데이터 스트림을 맵으로 편리하게 반환할 수 있어서 프로젝트나 알고리즘 문제를 풀 때 종종 사용했었다. 그런데 쓸 때마다 groupingBy() 메서드의 API 문서를 보며 아 이렇게 쓰는 거였지 하고 그대로 따라 치곤 했다.
public class GroupingByTest {
@Getter
static class Person {
private final int age;
private final String name;
public Person(int age, String name) {
this.age = age;
this.name = name;
}
}
public static void main(String[] args) {
List<Person> people = List.of(
new Person(10, "나"),
new Person(20, "너"),
new Person(10, "얘"),
new Person(10, "쟤")
);
Map<Integer, List<String>> map = people.stream()
.collect(Collectors.groupingBy(Person::getAge, mapping(Person::getName, toList())));
System.out.println(map); // {20=[너], 10=[나, 얘, 쟤]}
}
}그러다 한 번은 평소와 조금 다른 방식으로 이 메서드를 써야할 일이 생겼고, API 문서의 예시만 그대로 따라 치던 나는 처량하게 ChatGPT에게 달려갈 수밖에 없었다!
그래서 평소에 궁금했던 Collector의 내부 구조와 동작 방식에 대해 간단하게나마 공부해보았고, 그 내용을 정리했다.
Collectors.groupingBy()
먼저 groupingBy()의 간단한 사용법과 시그니처에 대해 살펴보았다. 메서드는 3개 정도로 오버로딩되어있지만 제일 많이 썼던 메서드(위 코드에서도 사용했던)를 가져와보면 아래와 같다.

API 문서는 아래와 같은데,

요약해보면,
- 이 메서드는 T 타입 입력에 대해 ‘group by’ 작업을 수행하는 Collector 의 구현체를 반환한다
- Function 타입의 classifier는 T 타입 입력을 K 타입의 key로 매핑한다
- Collector 타입의 downstream은 T 타입 입력을 받아 D 타입의 결과(value) 를 반환한다
- 결과적으로 반환되는 Collector는 Map<K, D> 을 생성한다
이 친구를 이해하기 위해서는 이 메서드가 반환한다는 Collector 인터페이스에 대해 더 정확히 이해할 필요가 있어 보였다.
Collector
개요
Collector의 API 문서는 조금 긴데, 나름대로 번역 & 요약해 보면 아래와 같다.
(병렬 처리 관련은 대부분 생략하였으며 오역이 있을 수 있으니 원문 참고 부탁드립니다)
- Collector는 가변 결과 container에 입력 원소들을 누적하는 가변 reduction operation을 정의한다
- 선택적으로 누적이 완료된 결과를 다른 표현으로 변형할 수 있다
- reduction operation은 순차적으로 또는 병렬로 실행될 수 있다
- 가변 reduction operation의 예시로는 원소들을 Collection으로 누적하거나 문자열을 StringBuilder를 사용해 concat 하거나 원소들의 sum, min, max 등을 구하는 연산들이 있다
- Collector는 원소를 가변 결과 container에 누적하기 위해 사용되는 (또한, 선택적으로 결과를 변형해주는) 아래의 4가지 추상 메서드를 통해 정의된다
- Supplier supplier() - 새로운 결과 container를 생성
- BiConsumer<A, T> accumulator() - 새로운 입력 원소를 기존 결과 container에 결합
- BinaryOperator combiner() - 두 개의 결과 container를 병합
- Function<A, R> finisher() - 결과 container에 대해 마지막 (선택적인) 변형 연산을 수행
- 내부에 Characteristics 라는 enum을 정의하여 연산의 특성을 명시할 수 있다
- CONCURRENT - 이 Collector의 누적 연산이 서로 다른 쓰레드에서 병렬로 처리될 수 있음
- UNORDERED - 이 Collector의 연산이 입력 순서를 유지함을 보장하지 않음
- IDENTITY_FINISH - finisher() 에서 변형 연산을 수행하지 않음. 따라서 결과 container의 타입 A 에서 최종 타입 R 로 unchecked cast를 수행해도 오류가 발생하지 않음을 보장.
- static 팩토리 메서드 of(Supplier, BiConsumer, BinaryOperator, Characteristics…) 를 통해 직접 Collector의 구현체를 만들어 사용할 수도 있다
- Collectors 클래스에서 Collector 를 구현하는 여러 편의메서드를 제공한다
- groupingBy(), toList(), toSet(), joining() 등이 여기에 해당
reduction operation?
API 문서 내내 등장하는 reduction operation은 동일한 combining 연산을 수행하며 입력 스트림을 하나의 결과로 만드는 연산으로, fold 라고도 불린다. 예를 들면 아래와 같은 연산이 있을 수 있다.
int sum = numbers.stream()
.reduce(0, (x, y) -> x + y);이는 풀어쓰면 아래 코드와 같다.
int sum = 0;
for (int x : numbers) {
sum += x;
}개인적으로는 학교에서 Ocaml로 함수형 프로그래밍을 처음 배울 때 fold라는 개념을 처음 접했었는데 자바에서 다시 만나 반가웠다.
(https://cs3110.github.io/textbook/chapters/hop/fold.html)
타입 파라미터
API 문서에도 적혀있지만 Collector는 T, A, R 이라는 3개의 타입 파라미터를 사용한다.
- T - reduction 연산의 대상이 되는 입력 원소
- A - 누적 결과 컨테이너의 타입
- R - 최종 결과 타입 (Characteristics.IDENTITY_FINISH 인 경우 A == R)
전체 동작 과정
지금까지 이해한 바로는 Collector는 단순히 연산 과정을 정의하는 도구이고 Collector의 API를 적절히 호출하여 누적 연산이 수행된 결과를 얻을 수 있는 것 같다. API 문서의 가장 아래에 보면 Collector를 어떻게 사용해야 하는지가 명시되어 있다.

문서를 참고해서 전체 과정을 도식화해 보면 아래와 같다.
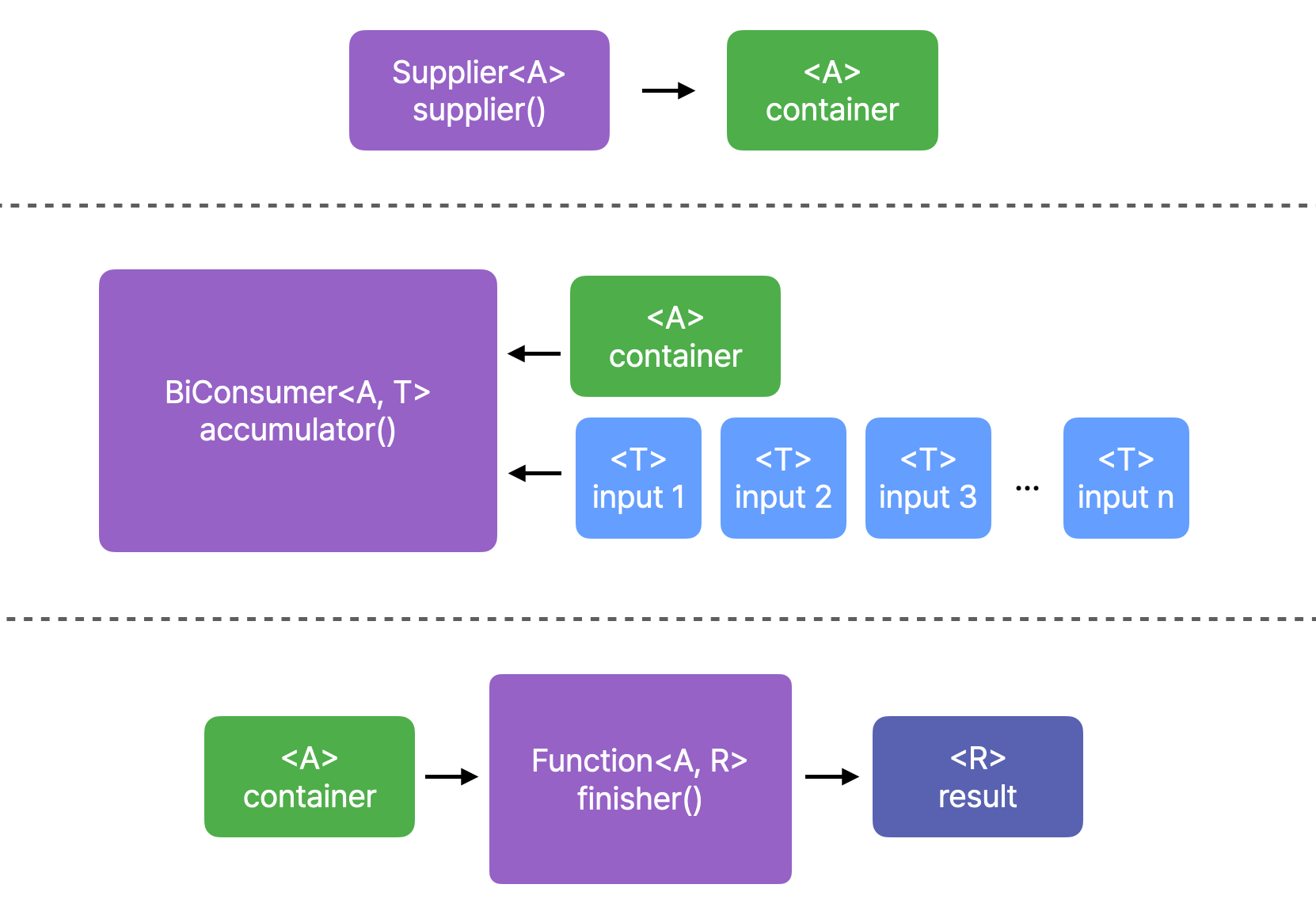
여기에 만약 accumulate 작업이 병렬로 수행될 경우, combiner() 메서드를 사용해 각각의 결과 container를 container로 병합하는 과정이 추가될 수 있다.
Stream.collect(Collector)
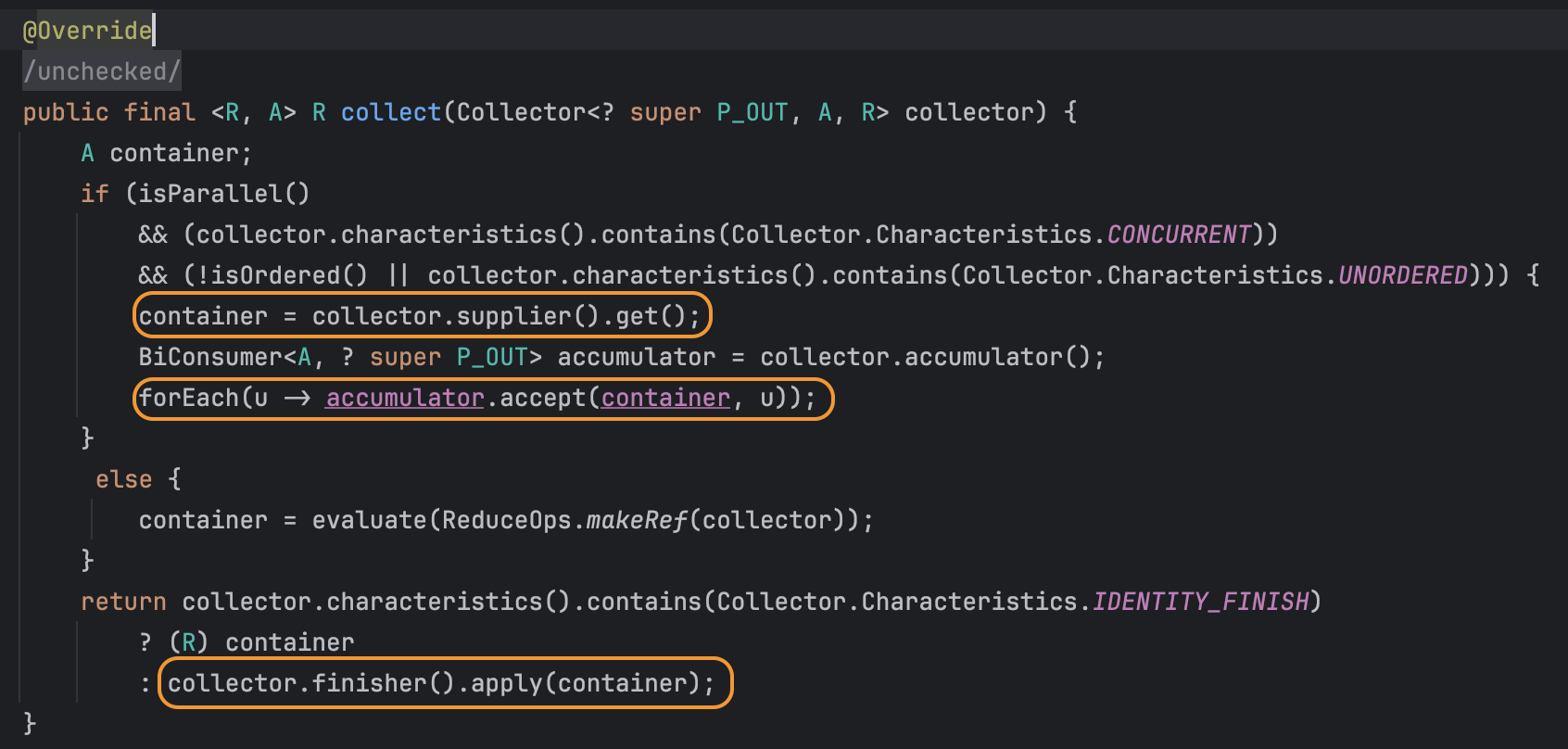
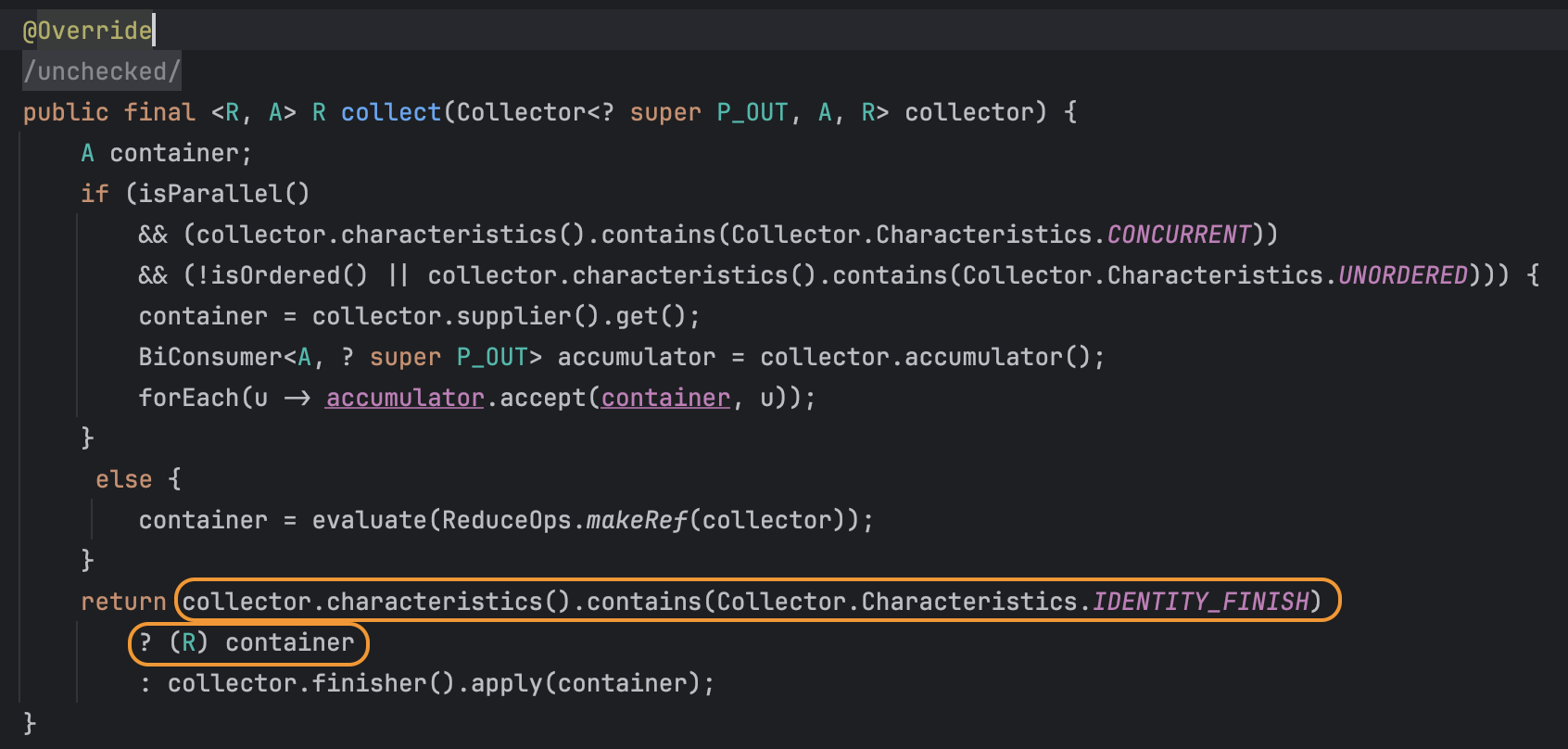
Stream에서는 데이터의 연산을 종결하기 위해 collect() 메서드를 사용할 수 있는데 이 메서드에서 위 그림의 과정을 진행하여 데이터에 연산을 수행하고 결과를 반환해 준다. Stream.collect()의 구현체는 ReferencePipeline 추상 클래스이며 아래와 같이 코드가 구현되어 있는 것을 확인할 수 있다.
Collectors
앞서 Collector의 API 문서에 적혀있던 것처럼 Collectors는 자주 사용되는 활용들에 대해 Collector의 구현체를 생성하는 편의 메서드들을 제공한다.
대표적인 예시로 toList()가 있다. 아마 스트림에서 아래와 같은 형태를 가장 많이 사용하지 않을까 싶은데
list.stream()
.map(...)
.sorted(...)
...
.collect(Collectors.toList());위 코드에서 마지막에 사용되는 toList()가 바로 Collectors의 편의 메서드이다.

Colletor의 구조를 이해하고 나서 다시 메서드를 살펴보니 이제야 어떤 식으로 Collector가 구성되고 사용되는지가 보였다. 먼저 toList()는 원소들을 리스트에 담아야 하므로 결과 container로 사용할 ArrayList를 생성하는 메서드 레퍼런스를 supplier()로 전달하여 사용하고 있는 것을 알 수 있다. 그리고 List.add() 메서드를 accumulator() 로 사용하여 앞서 생성한 ArrayList에 원소를 하나씩 담는다. 그리고 combiner()로 두 ArrayList를 병합해 주는 람다식을 넘겨준다.
그리고 마지막으로 CH_ID라는 상수를 넘겨준다. 위에서 사용된 CollectorImpl의 생성자는 아래와 같은데,

위 생성자는 finisher에서 별다른 작업을 하지 않는 경우 사용하는 생성자로 보인다. 실제로 CH_ID 상수를 확인해 보면 IDENTITY_FINISH 를 원소로 갖는 Set임을 알 수 있다.

IDENTITY_FINISH 이면 finisher()를 호출할 필요가 없으므로 toList()에서도 finisher()를 별도로 넘겨주지 않고 Stream.collect()에서도 결과 container를 바로 최종 반환 타입으로 형반환 후 반환하게 된다.
groupingBy() 동작 과정
그럼 이제 드디어 마지막으로, Collectors에 작성되어 있는 groupingBy() 메서드의 동작 과정을 다시 살펴보자. 먼저 이 글의 맨 위에 있는 (처음에 봤던) groupingBy() 코드는 아래와 같다.

이 메서드는 mapFactory 파라미터에 HashMap::new 를 넣어서 다시 아래의 시그니쳐를 갖는 groupingBy() 메서드를 호출한다.

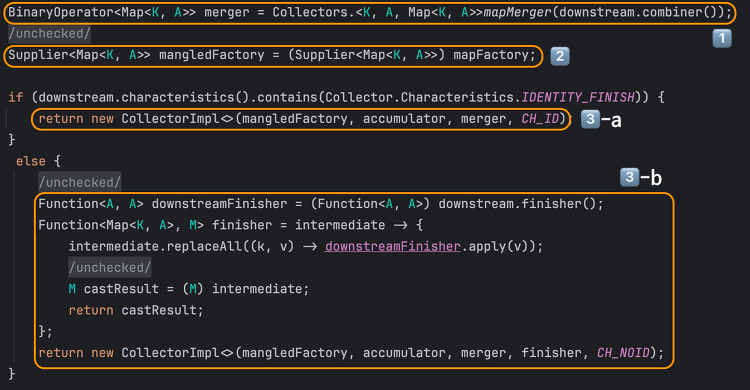
이 메서드의 전체 코드는 아래와 같다. 여기서 map의 value를 만들기 위한 downstream 도 Collector 타입이라는 것이 가장 중요한 부분이라고 생각된다. 즉, map을 Collector를 만들기 위해 또 다른 Collector를 사용하고 있는 것이다.
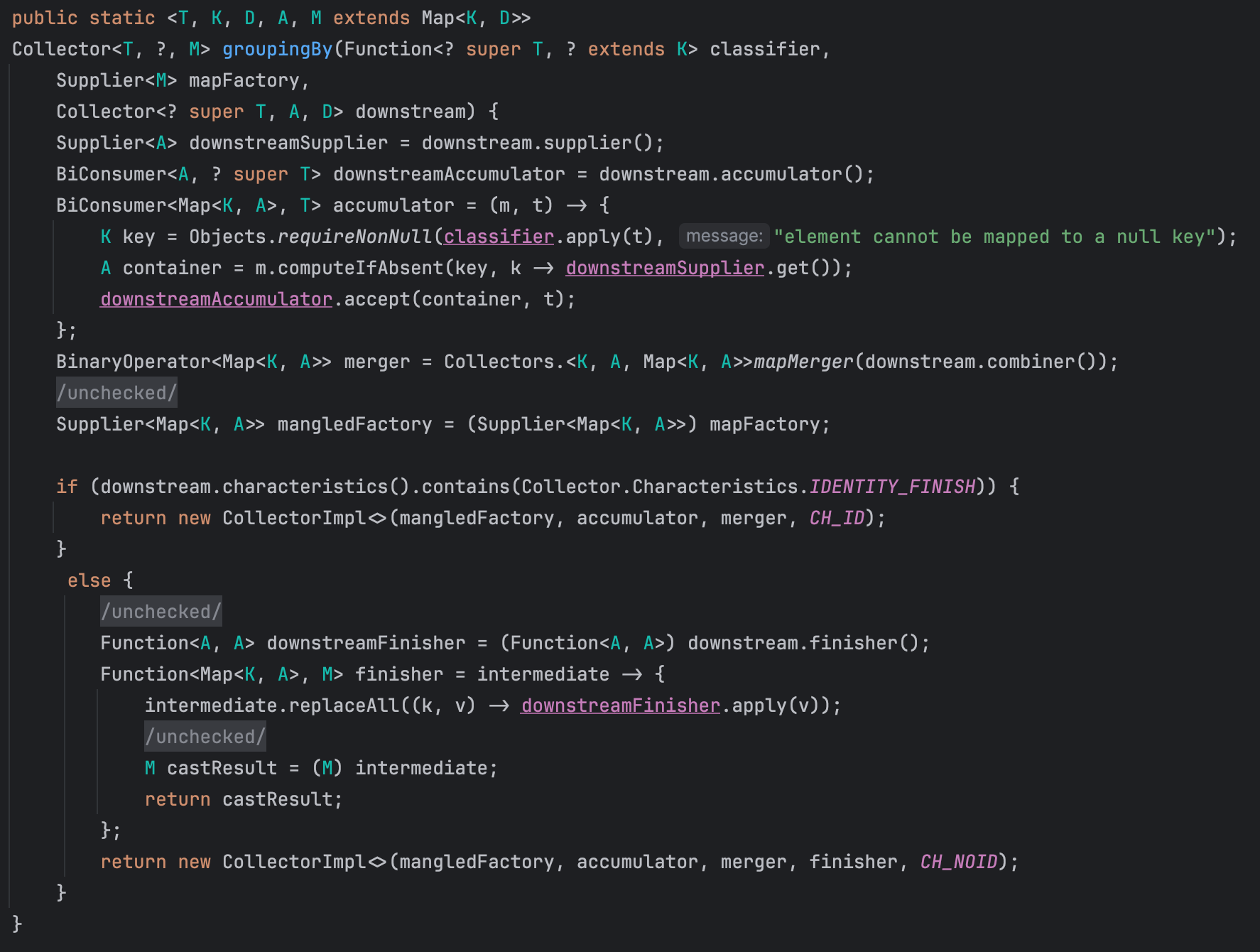
코드를 downstream Collector를 사용하는 윗부분과 새로운 Collector를 만드는 아랫 부분으로 나누어서 정리해 보았다. 먼저, 윗부분을 보면

- downstream의 supplier, accumulator를 변수로 뽑아둔다
- 입력 T를 통해 map을 만들기 위한 accumulator를 정의한다
- 먼저 classfier를 통해 입력 T에서 key를 추출하고
- Map m에 이미 key에 해당하는 value가 있으면 사용하고, 없다면 downstream에서 supplier()를 통해 map의 value에 해당하는 container를 생성한다
- downstreamAccumulator를 사용해 map value인 container에 입력 t를 누적한다
그리고 아랫부분을 보면,
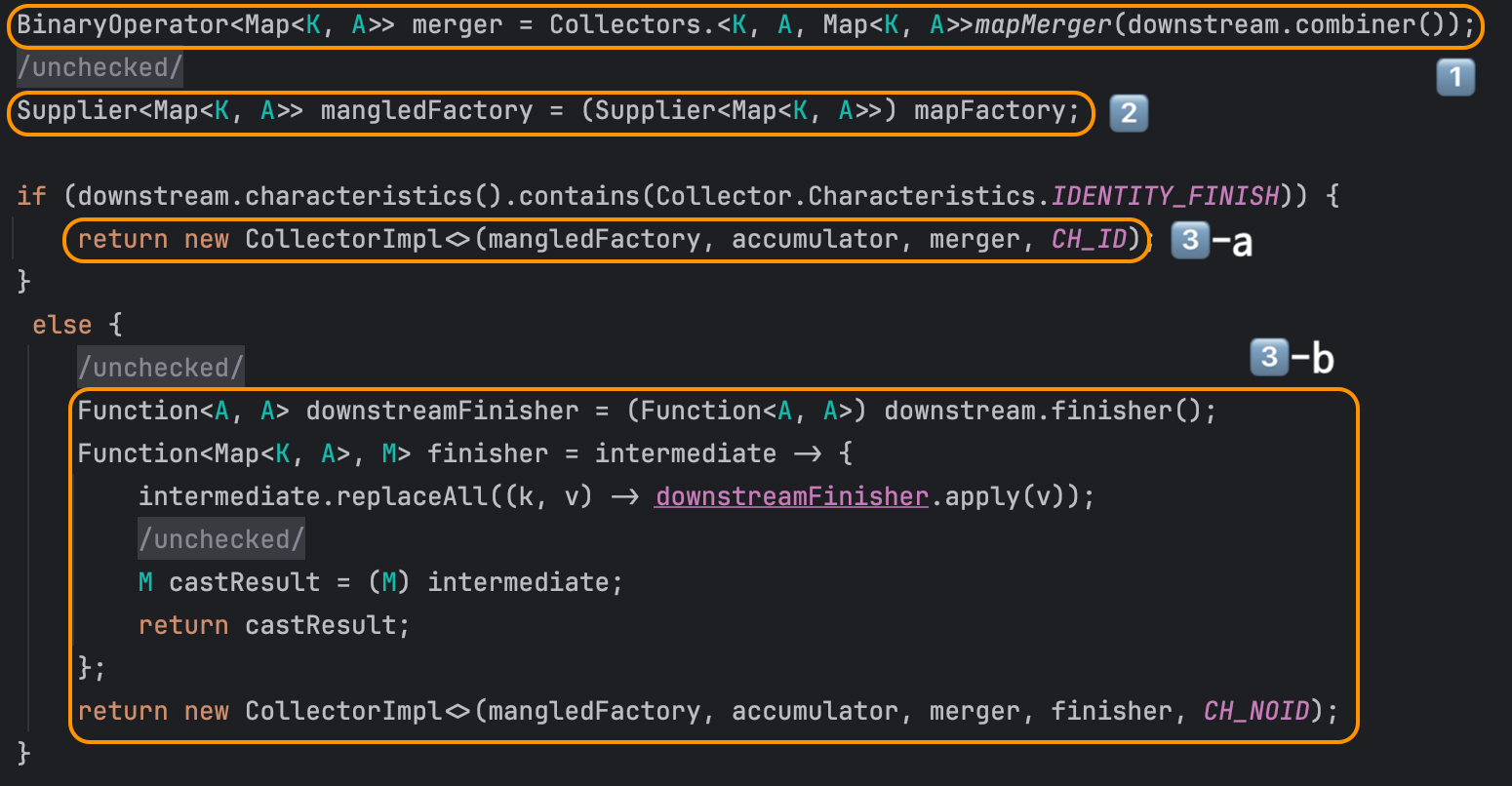
- 병렬로 연산이 수행될 경우에 대비해 동일한 key에 대한 여러 개의 map value를 merge할 때 사용할 merger를 만든다
- mapFactory의 타입을 key K, value A에 맞게 변환해준다
- Collector의 구현체를 생성한다
- CH_ID의 경우 finisher 없이 바로 구현체를 생성하고,
- 반환 타입이 결과 container와 달라지는 CH_NOID 의 경우 finisher를 만들어서 같이 전달한다
정리해 보면, classfier 를 사용해 입력 T에서 key를 추출하고 downstream Collector의 supplier와 accumulator를 사용해 입력 타입 T를 원하는 타입으로 변환하여 map에 누적하는 새로운 accumulator를 만든다. 그리고, mapFactory와 새로운 accumulator, merger를 갖는 새로운 (map을 만드는) Collector의 구현체를 반환한다. 여기서 반환된 Collector는 Stream.collect()에서 호출되어 실제 Map이 만들어지게 될 것이다.
맨 처음 예시
맨 처음에 봤던 groupingBy() 메서드의 API 문서를 다시 살펴보면,

groupingBy()의 downstream 인자에 mapping() 메서드의 결과를 전달하는 것을 볼 수 있다. 이 메서드 또한 Collectors에 위치한 메서드로
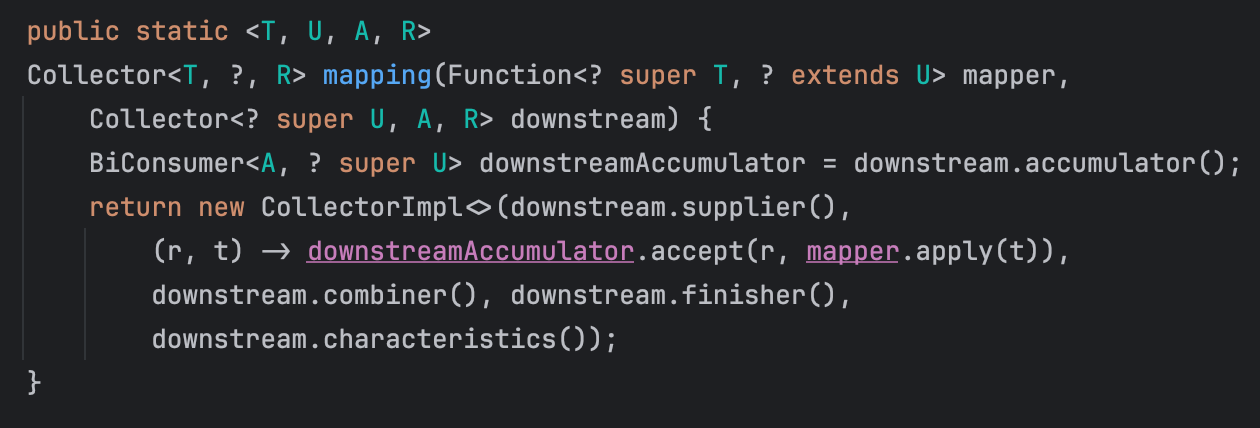
내용을 보면 또다시 Collector를 중첩해서 사용하는 것을 알 수 있다 (..ㅎㅎ) 근데 사실 간단하다. 입력 T를 어떻게 value의 원소로 매핑할지를 결정하는 mapper와 mapping된 값을 맵의 value(일반적으로 Collection)에 어떻게 누적할지를 결정하는 downstream Collector로 구성되어 있다.
downstream의 supplier()를 통해 결과 container를 만들고 거기에 mapper.apply(t)를 호출하면서 계속해서 매핑된 입력을 누적하는 accumulator 람다식을 갖는 Collector 구현체를 반환하게 된다.
응용
Collector의 구조를 이해했으니 이제 이걸 응용할 수 있다! 예를 들어 기존에는 Collectors.mapping 메서드를 사용해서 매핑된 입력을 list에 누적하여 map을 만들었지만, 그냥 단순하게 key 별로 개수를 세도록 할 수도 있다.
public static void main(String[] args) {
List<Person> people = List.of(
new Person(10, "나"),
new Person(20, "너"),
new Person(10, "얘"),
new Person(10, "쟤")
);
Map<Integer, Integer> map = people.stream()
.collect(Collectors.groupingBy(Person::getAge,
Collector.of(() -> new int[1], (arr, i) -> arr[0] += 1, (arr1, arr2) -> {
arr1[0] += arr2[0];
return arr1;
}, arr -> arr[0]))
);
System.out.println(map); // {20=1, 10=3}
}이렇게 하면 key 별 개수를 세준다. 그런데 사실 이거랑 거의 똑같은 메서드가 이미 Collectors에 정의되어 있다 ㅋㅋ

위 메서드 말고도 엄청 다양한 편의 메서드가 존재한다. 그래서 사실 Collectors를 직접 구현해서 사용할 일은 없을 것 같지만 구조를 이해하고 어떻게 동작하는지 확실히 정리해둘 수 있어 좋았다.



